Spark on Azure: a Gentle Introduction at Cloudbrew '15
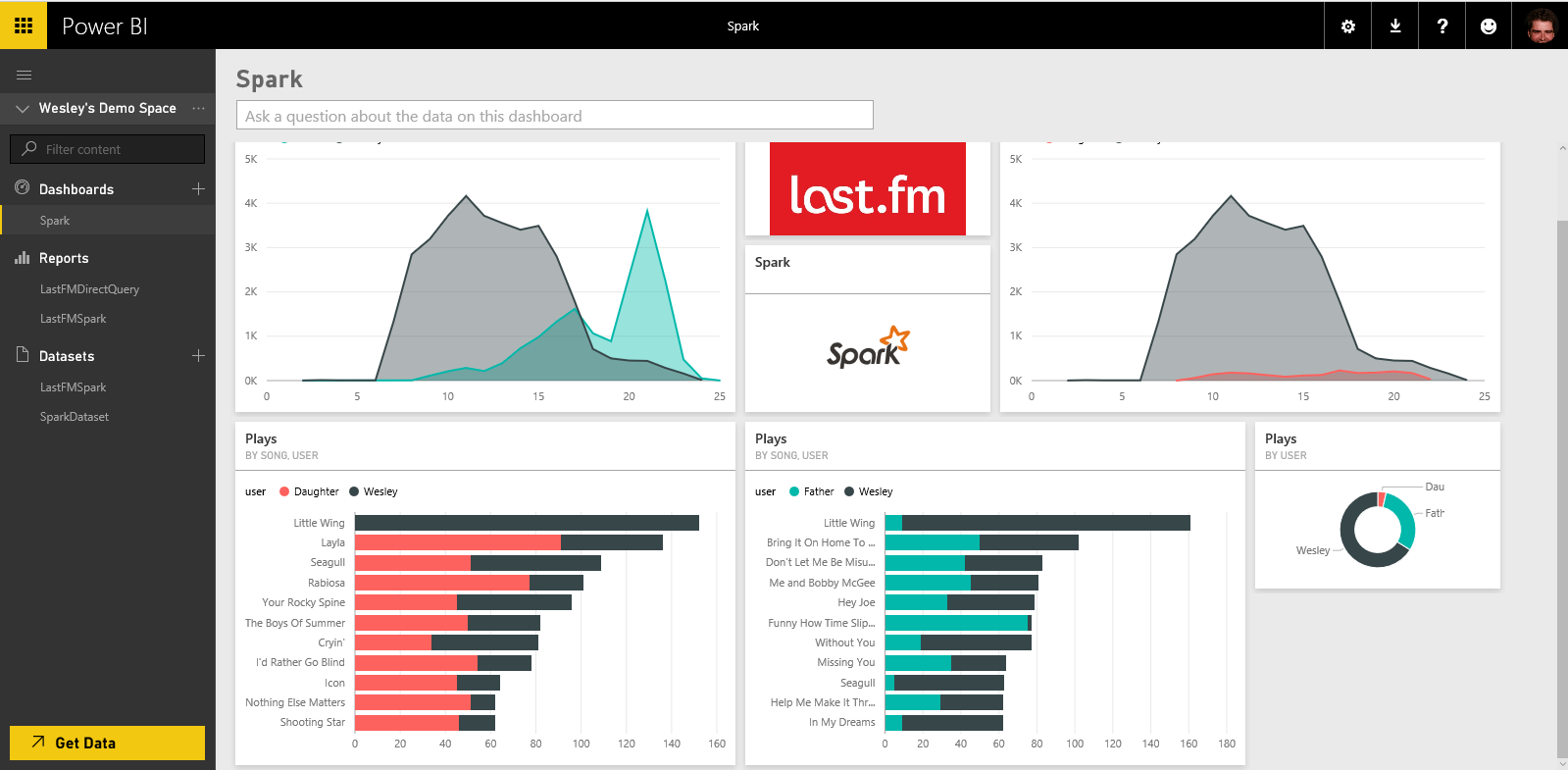
A gentle introduction to the world of Big Data and Spark. We are going to use Spark notebooks (Jupyter and Zeppelin), which are available on Azure HDInsight to demonstrate the ideal ad-hoc data analytics environment, right from within your browser. Apache Spark is the more or less successor to Hadoop, bringing both a batch and streaming execution model. Once the data is processed we will integrate Power BI on Apache Spark in an interactive way, to build a nice dashboard and visualize our insights.
Demo
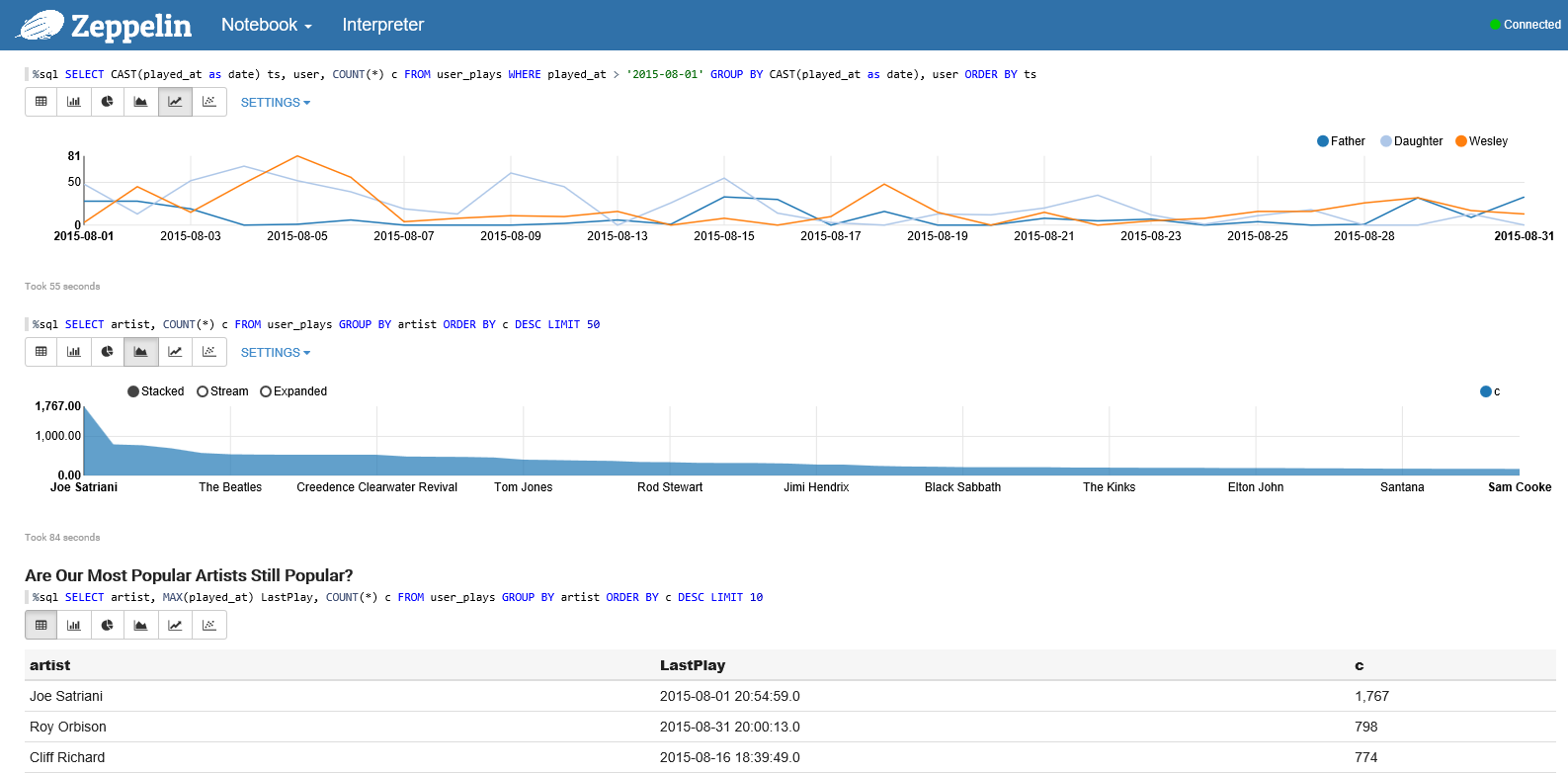
Wesley Backelant and I gave a demo, more or less based on: